
January 2024 Update
January has been our most productive month to date.
We've successfully migrated our entire platform to a new, more efficient architecture. Our new Radars and Evaluations features are now publicly available to all users on Unlimited or self-hosted plans, and we've pushed a lot of usage improvements to the app.
Platform Overhaul
We've revamped our entire source code and eliminated the need for Vercel and Supabase, leading to several improvements:
- Enhanced scalability of the app
- Access to all dashboard data via the API
- 10x increase in our speed of rolling out new features
- Less security concerns and error-surface associated with 3rd-party dependencies
- Simplified self-hosting setup
- Quicker dashboard performance
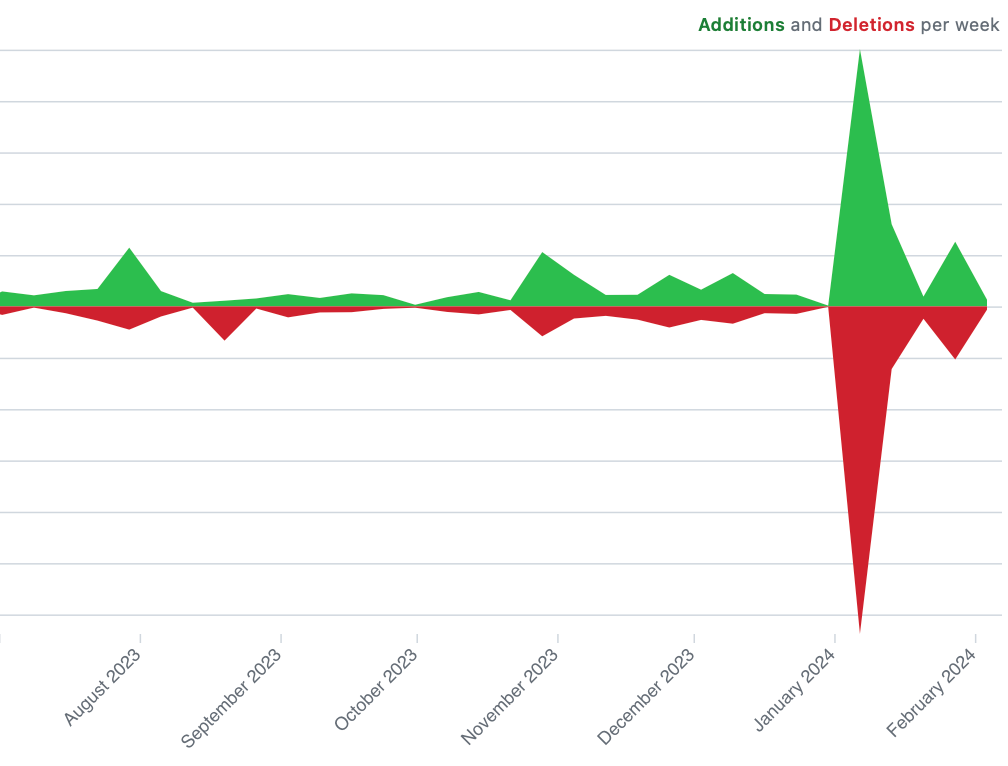
This is what it looks like in our GitHub graph:
Radars
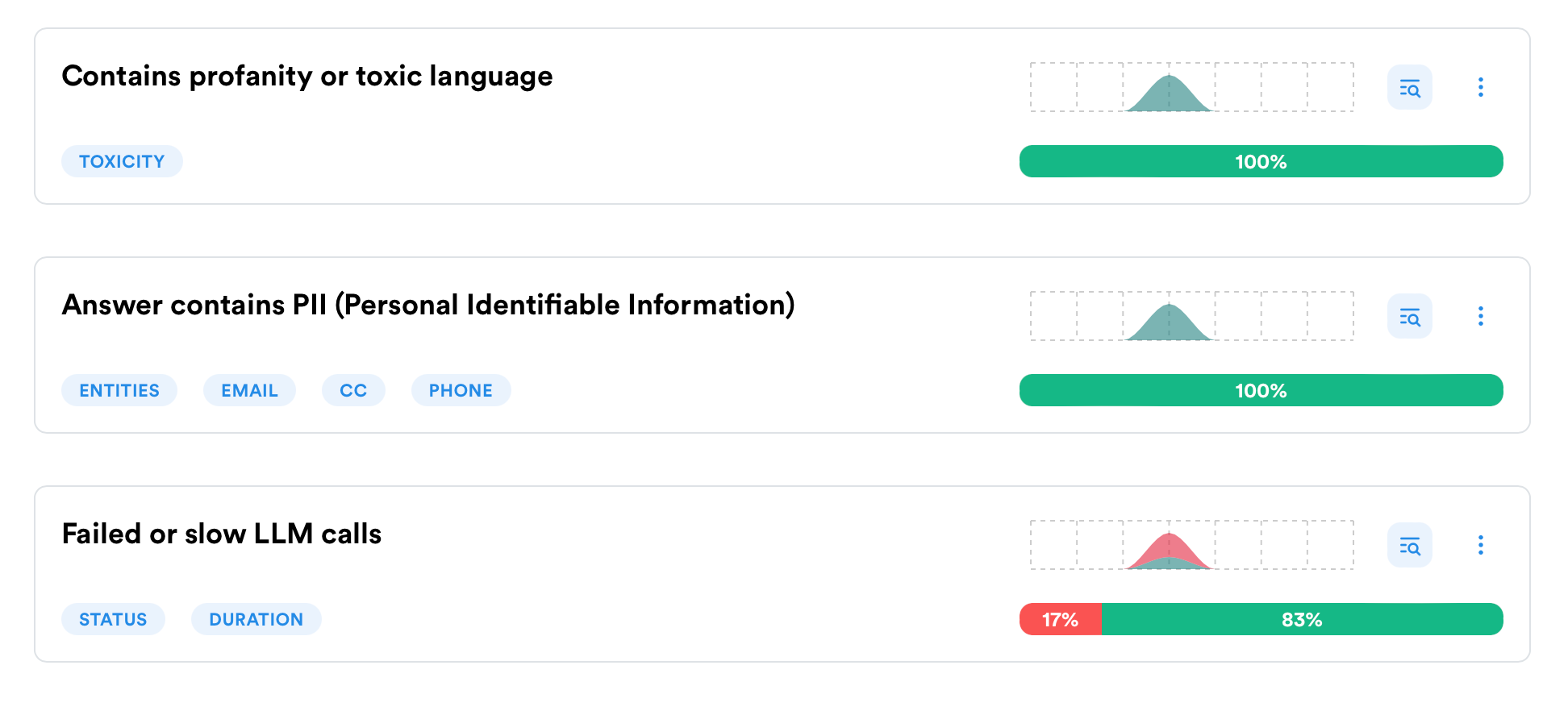
Radars have moved out of private access.
Radars are AI-powered alerts that monitor your runs for specific conditions, such as personal data, profanity, or negative sentiment.
Internally, we've deployed efficient, lightweight AI models that scan runs without relying on external API queries, perfect for self-hosted setups.
Evaluations
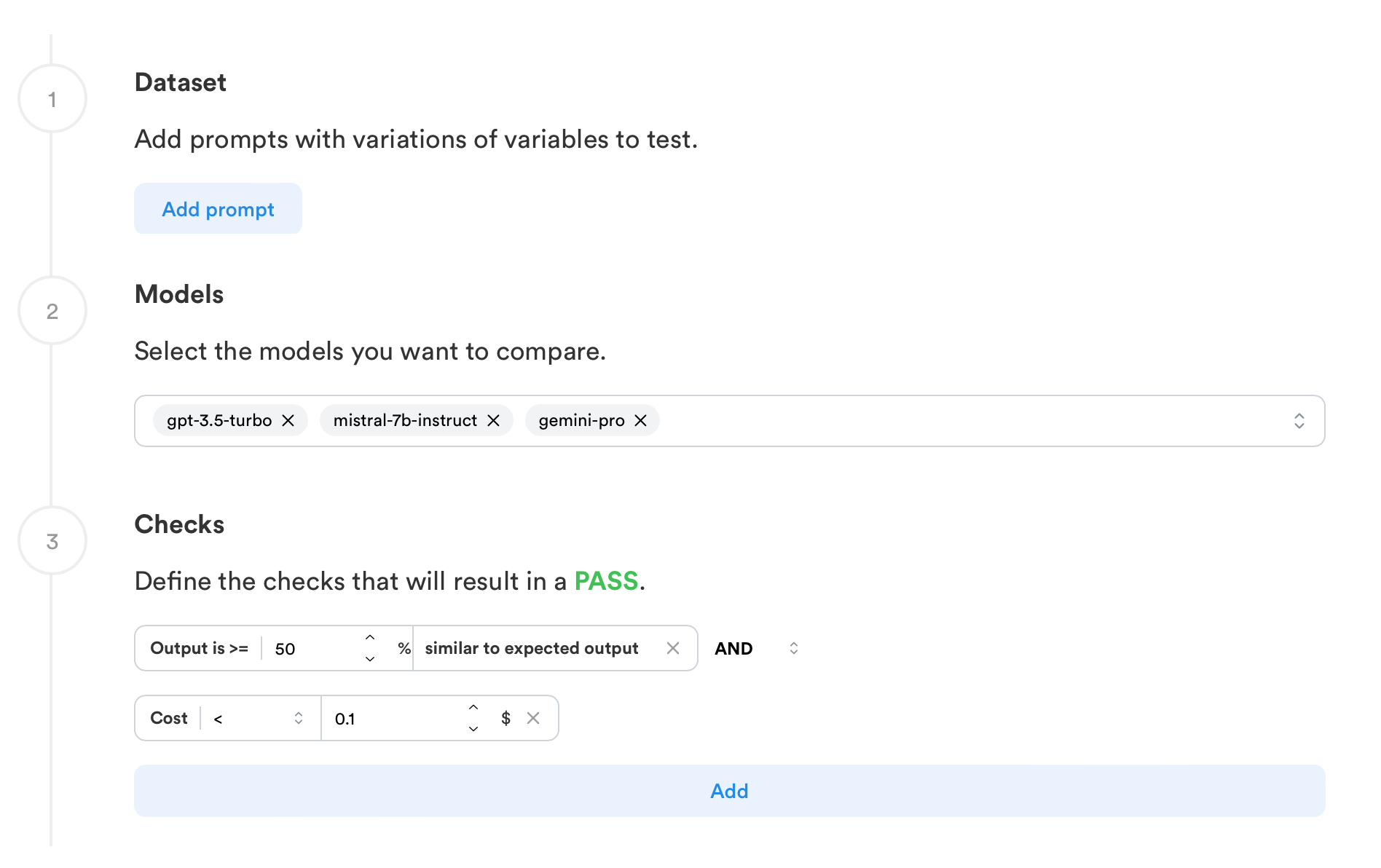
We've reimagined LLM evaluations from scratch, opting for no-code approach.
You can design and execute evaluations directly from the dashboard without needing to be a Python expert or have prior evaluation experience.
This is made possible through intuitive blocks that assess various aspects like:
- How closely your model's outputs match an ideal output
- The presence of hallucination in responses
- Usage of costs and tokens
You can create evaluations with 20+ models, including open-source options like Mistral, directly from the dashboard.
Some evaluation scenarios still require code---say for testing your custom agents or integrating into a CI pipeline---we will soon release the Evaluation SDK. This allows for the execution of dashboard-created evals your codebase, enabling contributions from both technical and non-technical team members.
We're continuously refining these features and are open to providing private access to the Evaluations SDK to those interested.
App Enhancements
We've pushed a lot of improvements to the app, such as:
- Merged "LLM Calls", "Chats" and "Traces" into a single "Logs" page, improving filters and search functionality across all data types.
- New filtering engine with a lot of additional filters (with more on the way).
- Add tool calls to templates and preview them in your runs.
- Button to duplicate templates
- Improved filter and dashboard speed.
- Simpler navigation around the app
Alongside these updates, we've made numerous fixes and are focused on extending these advancements to more affordable plans as we further optimize and reduce costs.
We're eagerly await your feedback :)
Also, if anyone in San Francisco wants to meet up with the founders, we're here for the month. Hit us up!